
Kafka on AWS: Architecture, Trade-offs, and a Production Baseline
March 2, 2026Kafka on AWS works extremely well — but it requires aligning two different models of thinking:
- Kafka’s distribution model
- AWS’s infrastructure and pricing model
Kafka assumes explicit control over replication, partition placement, and failure domains. AWS abstracts infrastructure into availability zones, instance families, EBS volumes, and cross-AZ networking costs.
When these models are not consciously aligned, the resulting architecture often behaves in surprising ways — technically and economically.
This is a long-form architectural deep dive. It is meant to clarify trade-offs and common misconceptions around Kafka and MSK on AWS. Approx reading time is 20 minutes. If you are looking for a quick guidance on a minimal base architecture, skip to the “A Production Baseline on AWS” section.
A Simple Imbalance Example
Consider a cluster deployed across three availability zones for high availability.
The intention is correct: distribute brokers across AZs to survive zone failure.
Now imagine:
- 10 brokers
- 3 availability zones
- Replication factor = 3
- 3 topics
With 10 brokers, it is impossible to distribute brokers evenly across 3 AZs. One zone will inevitably contain 4 brokers while the others contain 3.
That imbalance already introduces asymmetry.
Now consider the topics. If each topic is replicated across all AZs, partition placement will attempt to distribute replicas evenly — but perfect symmetry is mathematically impossible. The situation is typically a little more complex in the real world as topics are actually split into partitions. More on that in Partitions: The Real Unit of Scaling section.
For example:
- Three topics with replication factor 3 require 9 total replicas (3 topics x 3 replicas each).
- Four brokers in one AZ
- Three brokers in the other two AZs
How should three topics distribute evenly across four brokers?
They cannot. One broker will always end up empty in this scenario. See also the following diagram for an illustration.
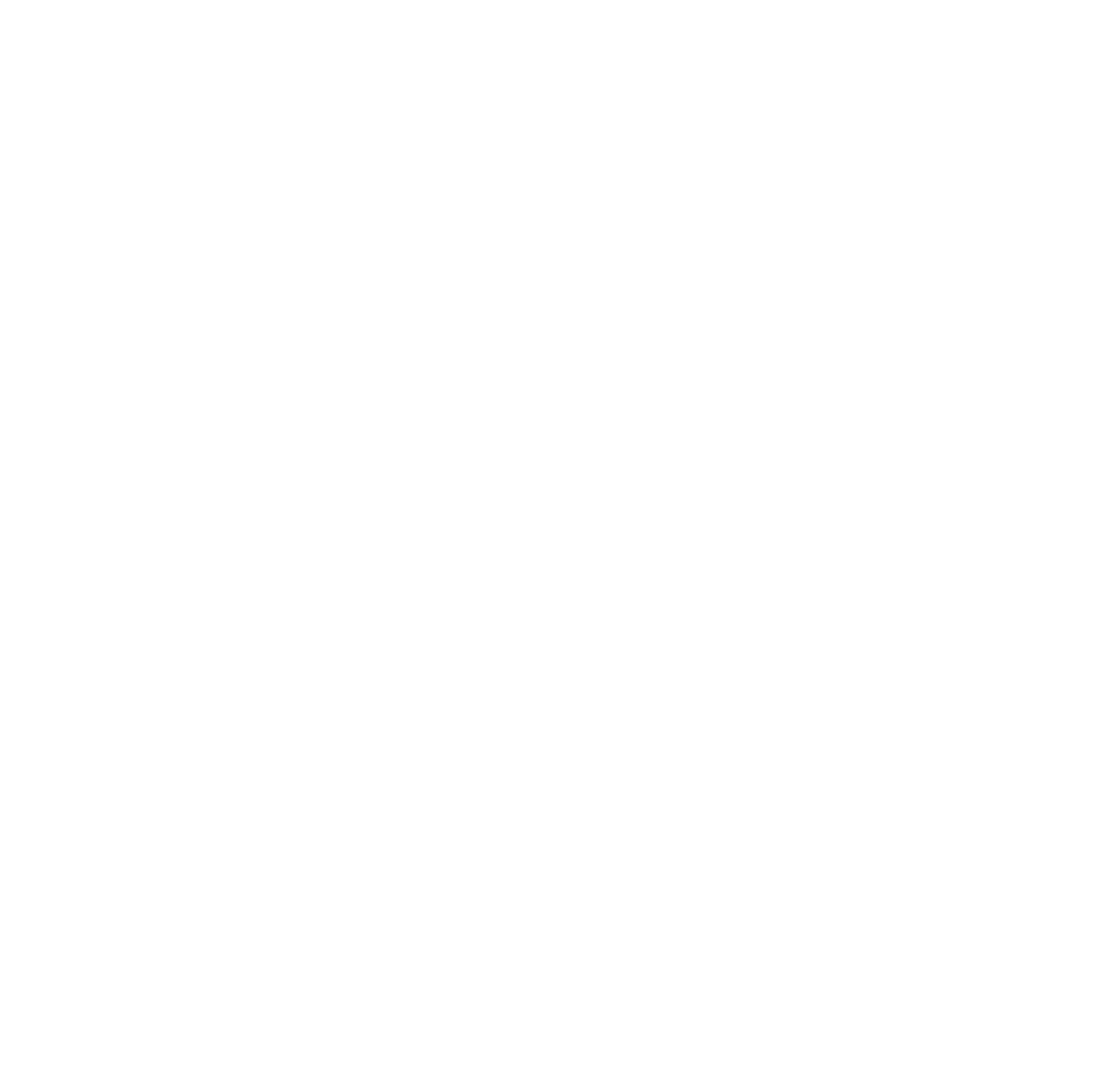
The result is subtle but important:
- Uneven partition leadership
- Uneven disk utilization
- Uneven network throughput
- Potentially uneven cross-AZ traffic
Nothing is “broken”. The cluster is technically correct.
But it is no longer symmetric and symmetry is often assumed when reasoning about capacity and failure behavior.
This is not a Kafka problem. It is not an AWS problem.
It is a distribution alignment problem.
The Second Layer: Infrastructure Physics
Kafka is often assumed to be memory-hungry.
In reality, Kafka does not maintain its own large in-memory message store. Instead, it relies heavily on the operating system’s page cache.
Writes are append-only. Flushes are sequential. Reads are typically sequential.
This means:
- Disk throughput patterns are predictable
- Memory primarily improves page cache effectiveness
- EBS throughput configuration matters significantly
- Network bandwidth is often the real constraint
However, optimizing around page cache behavior is not straightforward. The operating system ultimately decides what to keep in memory and what to evict. While more memory increases the probability of hot segments remaining cached, fine-grained control over caching behavior is limited.
As a result, simply increasing RAM does not guarantee proportional performance improvements. In many real-world workloads, network bandwidth or EBS throughput becomes the bottleneck long before memory does.
Choosing instance families solely based on RAM, or using burstable instances for sustained throughput workloads, ignores how Kafka actually interacts with the underlying system.
Again, nothing is “wrong”. But the mental model does not match the runtime behavior.
The Tooling Question
I often hear Kafka as the default answer to “we need messaging”.
Kafka is extremely powerful — but it is not just a messaging system. It is a distributed log with explicit durability semantics, replication mechanics, and operational characteristics. It is optimized for high throughput and horizontal scaling through partitioning. If you have real requirements that align with these strengths, Kafka can be a great choice.
Running Kafka — whether self-managed or via MSK — means:
- Paying for cluster uptime
- Managing replication behavior
- Understanding failure scenarios
- Planning capacity explicitly
Managed services such as SNS, SQS, EventBridge, or Kinesis abstract many of these concerns away entirely.
Kafka is a tool — not a goal. Most companies do not earn money by running Kafka clusters. They earn money by delivering products and services. Kafka may help achieve that, but it should not become the center of architectural gravity without necessity.
The Core Idea
Kafka on AWS does not become complex because either technology is unsuitable.
It becomes complex when Kafka’s internal distribution logic is deployed onto infrastructure whose failure domains, network characteristics, and pricing structure follow different rules.
Amazon MSK helps significantly with operating Kafka on AWS. It abstracts away broker provisioning, patching, and parts of cluster lifecycle management. In that sense, it reduces operational friction at the infrastructure layer.
However, MSK does not change Kafka’s fundamental distribution mechanics.
It does not guarantee even broker distribution across AZs. It will not automatically balance topics in mathematically asymmetric cluster layouts. It will not select instance types optimized for specific workload patterns.
MSK simplifies operations — but it does not remove the need to understand how Kafka behaves on top of AWS infrastructure.
The rest of this article explores how to consciously align these models — and when Kafka is the right tool to begin with.
Kafka’s Logical Model
Kafka is best understood as a distributed, replicated commit log.
That phrasing is not marketing language — it is the architectural core. Kafka’s primary abstraction is not “messages in a queue,” but ordered, append-only logs that are distributed across machines and replicated for durability. Message order is preserved per partition, not across an entire topic.
Once that mental model is clear, the rest of Kafka becomes much easier to reason about.
Topics: Named Logs, Not Queues
A topic is simply a named commit log (internally split into multiple partitions). When a team creates a topic such as orders, they are defining a log to which producers append records and from which consumers read.
Unlike a traditional queue, records are not removed when consumed. They remain in the log for a configurable retention period and can be replayed. This is a fundamental difference: Kafka optimizes for durability and replayability, not transient message passing.
However, a topic is not stored on a single machine. It is divided into partitions.
Partitions: The Real Unit of Scaling
A partition is an ordered, append-only log. Within a partition:
- Each message has a monotonically increasing offset.
- Messages are strictly ordered by offset.
- Writes are sequential.
- Reads are typically sequential.
This design is deliberate. Sequential disk access is predictable and efficient. Kafka leans heavily on this property.
If a topic has three partitions, it effectively consists of three independent logs. These partitions can live on different brokers and operate in parallel.
Partitions determine:
- Throughput
- Parallelism
- Replication layout
- Recovery behavior during failure
When scaling Kafka, partitions matter more than topics. Topics are logical groupings; partitions are where the physics happens.
Replication: How Durability Is Achieved
Each partition is replicated across multiple brokers. With a replication factor of three, there are three copies of the partition distributed across the cluster.
One replica acts as the leader. All writes and most reads go through that leader. The other replicas act as followers, continuously fetching and appending data from the leader to keep their logs in sync.
This leader-based model has two important consequences:
- Client traffic for a partition concentrates on a single broker — the current leader.
- Replication traffic flows from the leader to its followers.
In a multi-AZ deployment, that replication traffic will intentionally cross availability zone boundaries. High availability implies cross-zone data movement.
If the leader fails, one of the followers can take over — but only if it is sufficiently up to date.
That condition is formalized through the in sync replicadefinition (ISR).
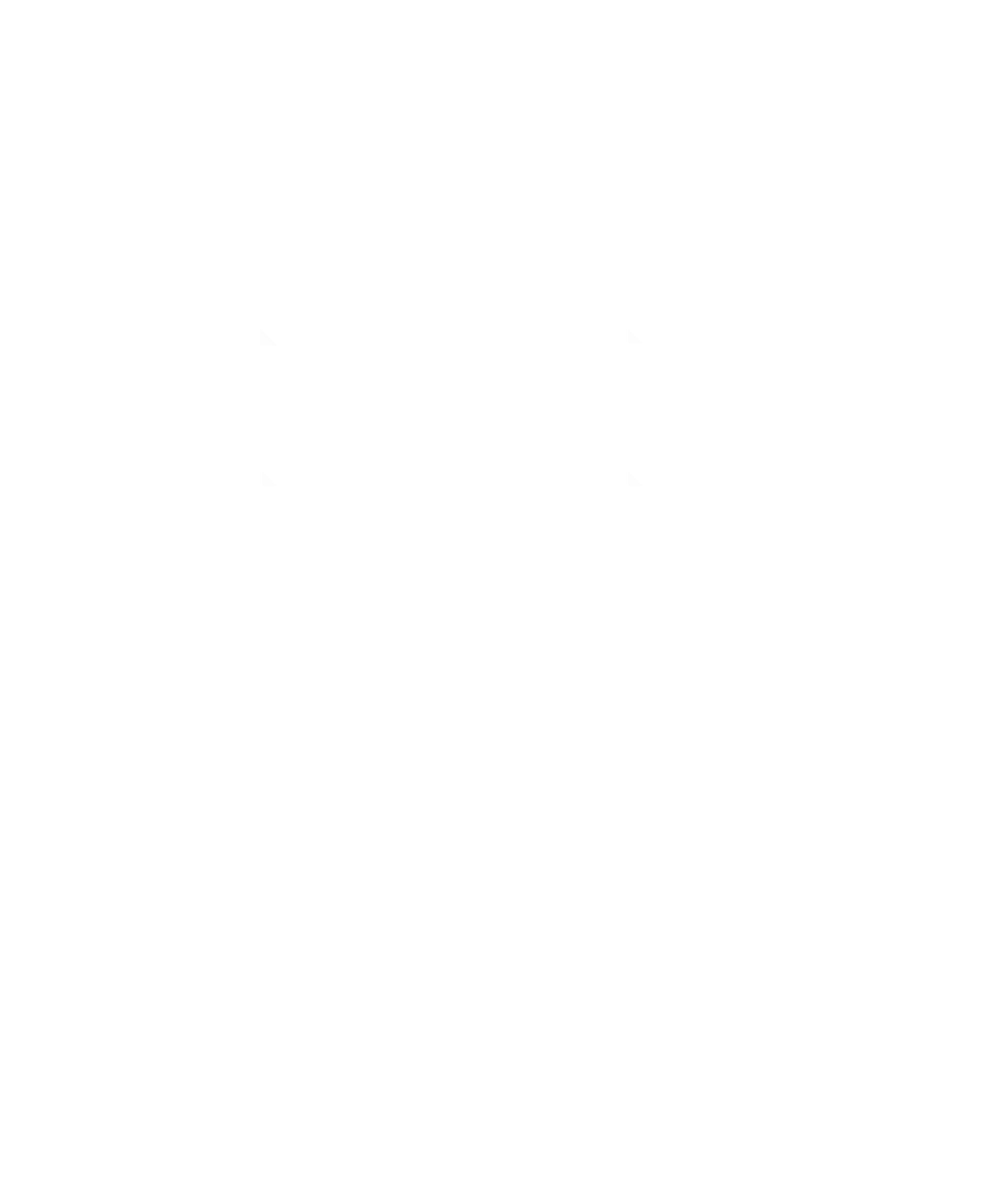
In-Sync Replicas and Write Guarantees
Kafka maintains an In-Sync Replica (ISR) set for each partition. A replica is part of the ISR set only if it has not fallen too far behind the leader as configured per topic.
When a producer is configured with acks=all, Kafka will only acknowledge a write once min.insync.replicas, a Kafka topic-level setting, have acknowledged the write. This means that if the replication factor is 3 and min.insync.replicas is set to 2, at least two replicas must acknowledge the write for it to be considered committed. This way you can define a quorum-based durability guarantee.
For example:
- Replication factor = 3
min.insync.replicas = 2
In this case, at least two replicas must acknowledge the write for it to be considered committed. If there are only two replicas in the ISR (e.g., one follower has fallen behind), the system can still acknowledge writes, but it cannot guarantee durability if another replica fails. If there is only one replica in the ISR, writes will be rejected to prevent data loss, since we require at least two acknowledgments for durability.
This setting defines the system’s durability guarantees. If one broker is down for maintenance and another falls out of the ISR, writes may start failing — not because Kafka is malfunctioning, but because the configured safety guarantees can no longer be satisfied.
Replication factor and min.insync.replicas are therefore not minor configuration details. They define how the system behaves under stress.
Consumers and Parallelism
Partitions also define how applications scale.
Within a consumer group, each partition can be assigned to at most one consumer at a time. This preserves ordering within a partition.
If a topic has three partitions and two consumers, Kafka distributes partitions as evenly as possible. One consumer will process two partitions; the other will process one.
If the same topic has six partitions and two consumers, each consumer can process three partitions. Parallelism increases.
However, parallelism is capped by partition count. If a topic has three partitions and four consumers, only three consumers will actively process data. The fourth will remain idle. Adding more consumers does not increase throughput unless the number of partitions increases as well.
Partition count therefore sets the upper bound for consumer parallelism.
Increasing partitions later is possible. Decreasing them is not. That asymmetry makes early sizing decisions more important than they may initially appear.
Why This Matters for AWS
Kafka’s logical model is explicit and deterministic:
- Partitions live on brokers.
- Leaders handle client traffic.
- Followers replicate over the network.
- Each partition maps to physical log files on disk.
When brokers are placed in AWS availability zones, these mechanics translate directly into infrastructure behavior:
- Replication becomes cross-AZ network traffic.
- Leader placement affects bandwidth utilization.
- Partition distribution affects disk usage symmetry.
- Failure domains map to AZ boundaries.
Understanding Kafka’s logical model is therefore a prerequisite for making sound infrastructure decisions.
With Kafka’s internal mechanics clarified, the question becomes how to map them onto AWS infrastructure in a predictable way.
A Production Baseline on AWS (EC2 or MSK)
Whether Kafka is operated directly on EC2 or through Amazon MSK, the fundamental mechanics remain the same.
MSK simplifies cluster provisioning and lifecycle management. Kafka’s replication, partitioning, and durability semantics remain unchanged.
For that reason, the architectural baseline described here applies equally to:
- Self-managed Kafka on EC2
- Amazon MSK (provisioned clusters)
The goal is not to start with the deployment flavor. The goal is to establish a topology and safety model that behaves predictably under load and during failure.
A Minimal Production Topology
A pragmatic production baseline looks like this:
- 3 brokers
- 3 availability zones
- 1 broker per AZ
- Equal broker distribution across AZs
This setup aligns Kafka’s failure domains with AWS availability zones. With replication factor 3, each partition can place one replica per AZ.
The primary benefit is not theoretical high availability. It is predictability.
With symmetric broker placement, capacity planning and failure reasoning become significantly simpler.
As soon as broker counts become asymmetric across AZs, subtle imbalance appears — especially under load or during failover. Partition and leader distribution can amplify or reduce that effect.
Symmetry reduces emergent complexity.
Safety Semantics Are Requirements-Driven
Once the physical topology is sound, the most important decisions concern durability and availability guarantees.
Kafka does not impose a single consistency model. These guarantees are configurable:
- Per topic (e.g., replication factor, ISR requirements)
- Per producer (e.g., acknowledgement level)
This allows a single cluster to serve different data classes with different safety expectations.
A simplified comparison illustrates the spectrum:
| Aspect | Durability / Consistency-Oriented | Availability / Throughput-Oriented |
|---|---|---|
| Typical use cases | Financial events, state transitions, irreversible business actions | Logs, telemetry, metrics, derived or reconstructible data |
| Replication factor | Often 3 | Often ≥1 (depending on tolerance) |
| Producer acknowledgements | acks=all | acks=1 or weaker |
min.insync.replicas | Requires quorum (e.g., 2 of 3) | Lower requirements |
| Unclean leader election | Typically disabled | May be tolerated |
| Behavior under partial failure | Writes may stop to preserve consistency | Writes continue, possible data loss |
| CAP trade-off | Favors consistency | Favors availability |
In a durability-oriented setup, Kafka will refuse writes if quorum cannot be achieved. This favors consistency over availability during certain failure scenarios.
In a throughput-oriented setup, the system may continue accepting writes under degraded conditions, accepting that some data loss is possible.
Neither column is inherently superior. The correct configuration depends entirely on the business cost of:
- Lost data
- Delayed data
- Service interruption
A 3-broker / 3-AZ topology does not force a consistency-first configuration — it simply makes quorum-based guarantees possible. The safety semantics remain a deliberate design decision.
Broker Sizing: Predictability Over Peak Numbers
Kafka clusters under sustained load are often constrained by network and storage throughput rather than raw CPU.
On AWS, the most important property of a broker instance type is predictable baseline network bandwidth.
Instance types advertising “up to X Gbps” can behave unpredictably when replication traffic and client traffic are continuous. Streaming workloads benefit more from guaranteed throughput than from burst capacity.
Memory plays a secondary role, primarily through the operating system’s page cache. More RAM increases the likelihood that hot segments remain cached. However:
- Cache eviction decisions are made by the OS.
- Fine-grained control is limited.
- Increasing RAM does not automatically increase throughput.
If memory is insufficient for the working set, symptoms tend to surface under load: increased disk reads, higher latency, and throughput variance.
In many real-world workloads, network or EBS throughput becomes the bottleneck before memory does.
Storage: Workload-Driven
Storage configuration should be derived from workload characteristics rather than copied from a generic template.
Relevant drivers include:
- Ingest rate
- Replication factor
- Retention period
- Acceptable recovery time after broker failure
- Consumer lag tolerance
Kafka’s append-only design produces predictable I/O patterns. That predictability should be used to calculate and validate expected throughput.
gp3 volumes can work well, but required throughput and IOPS depend entirely on the workload profile.
Partitions: Scaling with Intent
Partition count is often chosen casually — and that is where imbalance quietly begins.
When scaling Kafka, unevenness tends to show up in two places:
- At the infrastructure layer, where replicas distribute across brokers.
- At the application layer, where partitions distribute across consumers.
If either layer is slightly asymmetric, the system still works. But under load, the asymmetry becomes visible: one broker runs hotter, one consumer lags slightly more, replication traffic concentrates unevenly.
Individually, these effects are small. Collectively, they make the system harder to reason about.
So the practical question becomes:
How can partition count be chosen so that both layers remain balanced from the start?
Two constraints must be satisfied:
- Partitions should divide evenly across brokers (which is governed by the replication factor).
- Partitions should divide evenly across consumers (which governs application parallelism).
There is a simple way to satisfy both conditions at once.
Choose the smallest partition count that is divisible by both numbers.
In other words, use the least common multiple (LCM) of:
- the replication factor
- the number of consumers
For example:
If replication factor is 3 and there are 2 consumers:
- The smallest number divisible by both 3 and 2 is 6.
- Six partitions allow 2 partitions per broker and 3 per consumer.
- Both infrastructure and application layers are balanced.
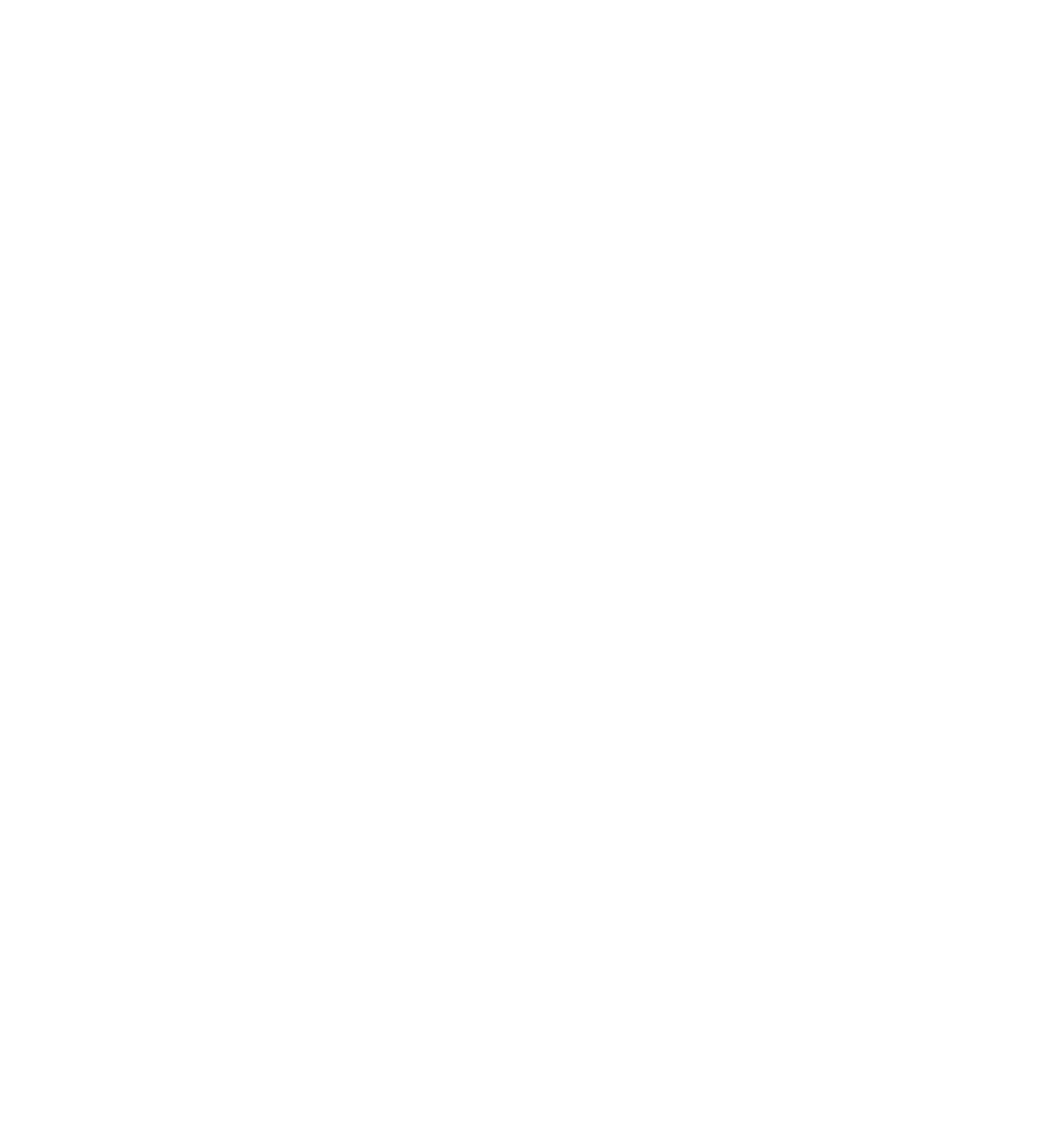
If there are 4 consumers:
- The smallest number divisible by both 3 and 4 is 12.
- Twelve partitions allow 4 partitions per broker and 3 per consumer.
The math is simple. The benefit is structural symmetry.
Kafka does not require this symmetry to function correctly. Uneven layouts are valid and often acceptable. But when symmetry is maintained deliberately, capacity planning and failure reasoning become significantly clearer.
The LCM rule is a heuristic as a safe baseline. It is not a universal law.
In practice, partition count is often driven primarily by throughput requirements, consumer processing cost, retention, and operational limits such as “partitions per broker”. These constraints can dominate the decision, and sometimes they force you into configurations that are not perfectly symmetric.
The point of the heuristic is different: it gives you a symmetry-preserving baseline that scales cleanly as you increase parallelism. The value of symmetry is not that it makes the cluster look nice on paper. The value is that it prevents structural imbalance from becoming a hidden multiplier under load.
In low-volume systems, asymmetry often does not matter. When traffic is small, the unevenness is below the noise floor. But at high throughput, small structural imbalances become operational problems: one broker becomes hotter, one consumer becomes the lag source, cross-broker traffic becomes uneven, and scaling feels unpredictable even when you “add capacity”.
That is why I treat symmetry as crucial. It is not mandatory for correctness, but it is a strong predictor of predictable behavior at scale. Start from a symmetric baseline, and when you increase partitions for throughput, increase in multiples that preserve that symmetry wherever feasible.
One final constraint remains: partitions can be increased, but never decreased. That makes deliberate initial sizing more important than it might first appear.
Amazon MSK: What It Solves and What It Doesn’t
Amazon MSK reduces operational burden at the infrastructure layer. The extent of that reduction depends on which MSK flavor is used: provisioned standard brokers, Express brokers, or Serverless.
Regardless of flavor, Kafka’s logical mechanics remain the same. Partitions, replication, ISR behavior, quorum semantics, and consumer parallelism all behave exactly as described earlier. Misunderstandings usually arise when operational abstraction is mistaken for architectural simplification.
Provisioned MSK (Standard Brokers)
Provisioned MSK behaves, from an architectural perspective, like Kafka running on EC2 with managed lifecycle operations. AWS provisions brokers, handles patching, integrates with IAM and VPC networking, and reduces operational friction. Kafka itself remains unchanged.
All structural decisions still have to be made deliberately:
- replication factor and topic defaults
- partition count and how it evolves
- consumer parallelism and balancing
- durability guarantees
- leader distribution and cross-AZ traffic
A common misconception is that “managed means we don’t need to understand Kafka internals”. Defaults are generally safe, but they are generic. They do not adapt to broker count, AZ layout, workload characteristics, or business requirements.
For example, the default replication factor used when creating topics does not automatically scale with cluster size. A three-broker cluster and a nine-broker cluster begin with the same defaults unless explicitly configured otherwise.
Safe defaults are not the same as correct defaults for a specific system.
Provisioned MSK also does not automatically redesign partition layouts when brokers are added. Scaling remains a structural exercise. The mechanics may be easier, but the architectural thinking is unchanged.
From a cost perspective, provisioned MSK is not pay-per-request. Brokers are billed per instance hour, plus storage and data transfer. Whether the cluster processes data or sits idle, the core infrastructure cost remains.
MSK Express Brokers
Express brokers change the trade-off.
They are designed for higher throughput per broker and faster scaling characteristics. In certain workloads, this can make them more efficient per unit of throughput than standard brokers.
However, Express is more opinionated. Configuration options are more limited. Certain Kafka parameters cannot be tuned freely. For example, durability-related settings such as min.insync.replicas are fixed to predefined values rather than configurable. See all immutable settings in the MSK documentation.
If those defaults align with workload requirements, Express can be a strong option. If a system requires specific quorum semantics or tuning flexibility, the reduced configurability becomes a constraint.
Express is therefore not a simplification of Kafka. It is a higher-throughput, more opinionated variant.
MSK Serverless
MSK Serverless abstracts broker management even further. Capacity is provisioned automatically, and the operational surface area is reduced.
Two misconceptions often follow.
The first is that serverless removes the need to understand Kafka. It does not. Topic design, partitioning strategy, consumer parallelism, and durability semantics still determine system behavior. The distributed systems properties remain intact.
The second is that serverless implies true pay-per-use. MSK Serverless is more usage-aligned than provisioned clusters, but it is not equivalent to request-based services such as SNS or SQS.
Serverless introduces billing dimensions that include cluster hours and partition hours, in addition to storage and data transfer. Partition count therefore becomes both a performance lever and a cost lever.
This creates a subtle cost trap.
Partitions are often increased to support peak parallelism. In a provisioned cluster, that primarily affects internal structure; you are already paying for the brokers. In Serverless, partitions themselves contribute to cost, even when idle. Because partitions cannot be decreased, a scaling decision made for peak throughput can become a permanent baseline expense.
Serverless reduces operational effort. It does not eliminate architectural trade-offs. It shifts where those trade-offs surface.
Architectural Responsibility Remains
MSK can reduce infrastructure management effort to various degrees. It does not design partition strategies, define durability semantics, or choose safety guarantees for you. You can pick your MSK flavour based on your requirements.
Kafka remains a distributed commit log whose behavior is determined by deliberate configuration choices. Managed infrastructure simplifies operations. It does not replace architectural intent.
Even with managed deployment options available, one fundamental question remains unchanged: why Kafka at all? Infrastructure abstractions do not remove the need to justify the tool itself.
| Aspect | Provisioned (Standard Brokers) | Express Brokers | Serverless |
|---|---|---|---|
| Broker management | You choose instance type and broker count | Higher throughput broker type with managed scaling characteristics | Broker capacity abstracted |
| Partition rebalancing | Manual / explicit scaling decisions | Automatic rebalancing | Abstracted from the user |
| Configurability | Broadest configuration control | Limited configurability | Limited configurability |
| Throughput profile | Depends on instance type and cluster size | Higher throughput density per broker | Moderate to high within service-defined limits |
| Scaling responsibility | Architectural decisions remain explicit | Some automation, architectural choices still required | Capacity scaling abstracted, partition strategy still required |
| Cost model | Broker instance hours + storage + data transfer | Higher per-broker cost, higher throughput density | Cluster hours + partition hours + storage + data transfer |
| Partition count impact on cost | Indirect (capacity utilization effect) | Indirect | Direct (partition hours are billable) |
| Best suited for | Workloads requiring full control and tunability | High sustained throughput with reduced operational tuning | Workloads prioritizing reduced operational overhead |
When Not to Use Kafka
The question is often framed incorrectly.
Instead of asking, “Why not Kafka?”, the more useful question is:
“Why should I use Kafka?”
Kafka is a distributed, replicated commit log optimized for sustained high throughput, controlled durability semantics, and replayable event streams. Choosing it should be a deliberate decision. There should be a clear reason to pick Kafka over simpler tools that already satisfy the requirements.
If the problem at hand is simple message distribution between services, especially on AWS, there are simpler tools available. SNS combined with SQS provides durable fan-out, retries, scaling, and operational simplicity without requiring engineers to reason about partition counts, replication factors, quorum semantics, or leader election.
Kafka’s design optimizes for:
- sustained high bandwidth
- horizontal scaling through partitioning
- explicit durability guarantees
- replayability of event streams
Those optimizations come with operational and configurational overhead. If none of these topics resonate with your actual requirements, Kafka is most likely not the first tool to reach for.
In small or moderate traffic environments, Kafka’s strengths often do not offset its complexity. The result can be a system that is harder to operate, harder to reason about, and more expensive than necessary.
Kafka Requires Distributed Systems Literacy
It is possible to deploy Kafka with very little knowledge.
It is much harder to operate Kafka responsibly without understanding distributed systems fundamentals.
Kafka is a quorum-based system. Its durability and availability guarantees are defined by:
- replication factor
- in-sync replica requirements
- producer acknowledgement settings
- leader election behavior
These parameters determine how the system behaves under failure. They define whether the system prefers consistency or availability in certain partition scenarios.
Understanding the CAP theorem and quorum semantics is not optional when operating Kafka in production. Replication factor, min.insync.replicas, acknowledgement settings, and leader election policies directly determine how the system behaves under partition or failure:
- quorum-based acknowledgement changes durability guarantees,
- insufficient in-sync replicas affect write availability,
- and leader election policies affect data safety.
Partitioning and replication must also be understood together. Partition count defines parallelism and scaling limits. Replication defines durability and cross-AZ traffic. These concepts interact.
Kafka is difficult to break accidentally. Defaults are generally safe. But safe is not the same as optimal.
If a configuration parameter is changed, it should be understood. If it is left unchanged, that should also be a deliberate decision rather than an assumption that “managed” implies correctness.
Where Kafka Shines
Kafka becomes compelling when:
- throughput is high and sustained
- multiple independent consumers need access to the same durable stream
- replayability is required
- durability guarantees must be explicitly controlled
- the system must scale horizontally in a predictable way
In such environments, Kafka’s architecture pays off. Partitioning enables parallelism. Replication enables controlled durability. Quorum semantics enable explicit trade-offs.
Conclusion
Kafka works very well on AWS.
It can provide high throughput, controlled durability semantics, and scalable event streaming across availability zones. When designed deliberately, it is predictable and robust.
But Kafka is not simple.
It exposes distributed systems mechanics by design. Replication, partitioning, quorum semantics, and consumer balancing are not implementation details. They define how the system behaves under load and during failure.
If there is a clear reason to use Kafka, and the system requirements justify its complexity, then running Kafka or MSK on AWS is entirely reasonable.
If those requirements are not present, simpler tools may achieve the same outcome with less operational and conceptual overhead.
Kafka is a powerful tool. It rewards teams that understand what it does and why they are using it.
If you made it this far, you might want to take a look at another article I wrote on my past experience with event driven architectures on AWS and what my take on different AWS native messaging services is.

With over a decade of hands-on AWS experience and certifications spanning Developer to Security Specialty, Robert works as a Cloud Consultant at superluminar. Here, he shares stories and insights from his work — from serious AWS challenges to playful experiments and everything in between.