
Data pipeline journey and the pitfalls
August 28, 2025
Background & Motivation
Nowadays, most blogs and tutorials focus only on the polished, “perfect” side of development, showcasing successes while glossing over mistakes and challenges. In this article, I want to take a different approach. I’ll dive into the messy, real-world side of building a ETL-pipeline, sharing the mistakes that happen, why they happen, and how to resolve them. My goal is to give you practical insights so you can avoid the same pitfalls and ultimately create a stable, reliable product.
Where We Began
We built our ETL pipeline (see Part 1) expecting the data to always be correct and follow the expected schema. But the real world had other plans. Data is not always consistent, and schemas are not always followed. To prevent our storage from being overwhelmed by invalid or inconsistent data, we needed a reliable way to safeguard and cleanse our inputs.
Discovering “Murphy’s law”
As discussed in Part 1, this is the pipeline we built. We thought, “It will be fine” since everything worked flawlessly in development and staging, but production was a different story.
Once we rolled out the solution, errors started piling up in the following days.
Why? Because we assumed the data would be “safe” and didn’t put proper verification in place. In the real world, things behave differently: network hiccups, accidental device disconnections, or simple latency issues can all cause unexpected problems.
Gradually, our ETL jobs started throwing more and more errors until they eventually stopped running, and our S3 buckets slowly turned into S3 trash cans.
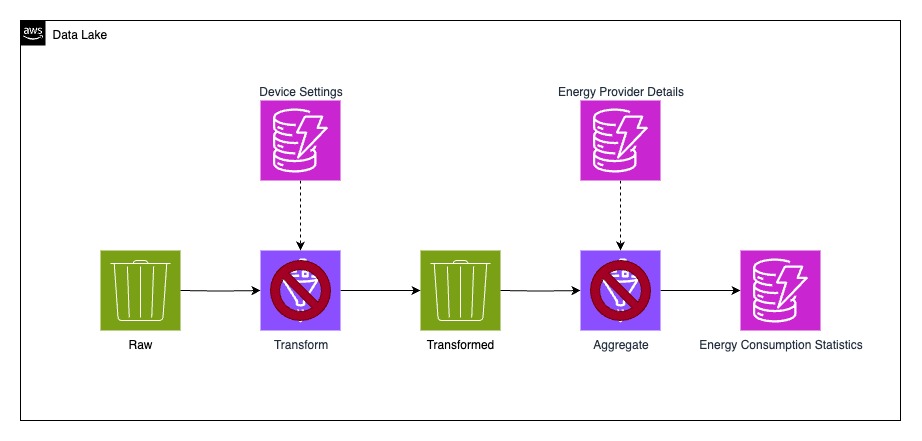
What happened?
Since we didn’t have any ingestion validation, we were basically accepting every message blindly. Because our system didn’t expose any public API and only received data from signed devices via MQTT, we thought, “What could possibly go wrong?”
Turns out, quite a lot. We were receiving incomplete events, missing properties, or values that were completely out of proportion.
At one point, it even looked like someone was running a nuclear power plant from at home! In reality, it was just a bug, we received Python’s maximum safe integer (263 - 1), which was stored as the currently produced watts.
How did we resolve it?
The plan itself was quite straightforward:
- Ensure that only valid data makes it into the system
- Clean up and sanitize the data that had already been stored
- Write a blog about the learnings
The technical implementation, however, was a bit more challenging.
As I mentioned in Part 1, I had never worked with ETL or AWS Glue before, so the process felt a lot like playing detective at a crime scene, digging through clues, piecing things together, and slowly unveil the mystery. 🕵🏻♂️
Ingestion Validation
To stop the chaos at the source, we added an ingestion validation step by attaching a data transformation Lambda to our Firehose stream. According to the Firehose documentation, every incoming event is first routed through this Lambda function before moving downstream.
The Lambda then returns an object with a property called result. This property decides the fate of each event and can be set to one of three values:
- Ok, The record is valid, proceed and store in
/valid - Dropped, The record is invalid, proceed and store in
/invalid - ProcessingFailed, The record is malformed, something went wrong and we drop it.
This mechanism gave us the control we needed: only valid, complete and realistic data made it into the system, while malformed data could be dropped before it had the chance to pollute our storage.
To give a little bit of insight: since I mostly code in TypeScript, I wrote this validation using Zod, which made it quite easy to implement our validation logic.
You can dive deeper into the official AWS documentation here: AWS Firehose Data Transformation
Sanitizing existing data
Fixing the ingestion pipeline was one thing, but what about the data that was already sitting in our storage? To deal with this, I created a new Glue job dedicated to cleaning up the mess.
The job took the existing data, validated each record, and then routed it back into the raw bucket, this time split into two separate folders: /valid and /invalid. That way, only clean data could move on, while the invalid records were isolated for inspection.
Surprisingly, this approach worked like a charm. Once the job was up and running, it quickly brought order back to our buckets and gave us a clear separation between trustworthy data and the outliers.
Note: I know S3 does not have folders, but to keep it simple, I call it folder instead of object-prefix.
Success!
After applying these changes, the pipeline finally recovered. Data started flowing through the stages successfully again, and we were once more seeing accurate results in our app. Case closed… or is it?
Yes, it was, but I would not be a good detective if I would not share why things were breaking in the first place, along with a few other interesting findings I uncovered along the way.
Mismatching Datatypes
Let me give you a simple example in JavaScript, since I’m most familiar with it and it’s often used to demonstrate the quirks of weakly typed languages.
If you open node in your terminal and run:
1 + 1
you’ll get the expected result:
2
Now try this instead:
'1' + 1
and the output will be:
'11'
Why? Because JavaScript is weakly typed and performs type coercion. In the second example, the number 1 is implicitly converted into a string, so instead of adding the two values numerically, JavaScript concatenates them into the string “11”.
JavaScript only comes with few Datatypes String, Number, Bigint, Boolean, Undefined, Null, Symbol, Object.
AWS Glue on the other hand looks quite different, especially when it’s about numeric values.
The Datatypes look like following:
byte: 1-byte integer from -128 to 127
short: 2-byte integer from -32768 to 32767
integer: 4-byte integer from -2147483648 to 2147483647
long: 8-byte integer from -9223372036854775808 to 9223372036854775807
float: 4-byte single-precision floating point numbers
double: 8-byte double-precision floating point numbers
decimal: max 38 digits, 18 after the decimal
string: Character string values
boolean: true or false
timestamp: Values comprising fields year, month, day, hour, minute, and second
date: Values comprising fields year, month and day
So if you have a calculation in your code which for example would try to sum daily_import_energy from those objects:
{
"device_id": "01234ABCD",
"timestamp": "2025-08-01T00:00:00",
"daily_import_energy": 30000 // fitting into "short"
}
{
"device_id": "01234ABCD",
"timestamp": "2025-08-01T00:00:00",
"daily_import_energy": 3000000 // fitting into "integer"
}
Glue will not try to resolve this as 30000 + 3000000 but rather as:
{"short": 30000, "integer": null} + {"short": null, "integer": 3000000}
Which will definitely fail horrible, since Glue is not weakly typed or has type coercion
For those cases Glue implemented resolveChoice, here is a good example:
“Data preparation using ResolveChoice, Lambda, and ApplyMapping”
The real meaning of the transformed stage
AWS describes the transformed stage as following:
This bucket consists of transformed data normalized to a specific use case for performance improvement and cost reduction. In this stage, data can be transformed into columnar data formats, such as Apache Parquet and Apache ORC, which can be used by Amazon Athena.
Think of the transformed stage as the point where your raw data gets a proper makeover. Up until now, data may be messy, inefficient, or stored in a way that’s not very friendly for analysis. In this stage, the data is reshaped and optimized for specific use cases, making it faster to query and cheaper to store.
One thing here is to convert the data into columnar formats like Apache Parquet or Apache ORC.
Imagine a giant spreadsheet: instead of storing every row one by one, these formats organize and compress data by columns. The result? Queries run much faster (since you only read the columns you need) and storage costs drop significantly. This is especially useful in aggregation queries where you create, e.g., a sum or other aggregations over a column.
In short, the transformed stage is where raw data becomes clean, efficient, and ready for analysis or further processing.
So what does this mean in practice? We dropped a lot of unnecessary columns that we don’t need for this use case.
To put numbers on it, we went from 46 down to just 7 columns. On top of that, we switched the storage format to Parquet, which, thanks to its efficient compression, cut our storage size by 98%!
These changes did not just save space, they also made the pipeline way faster. With less data to process and a more efficient format, our Glue jobs dropped from around 15–20 minutes to a maximum of 2 minutes (including boot and teardown).
And the cherry on top? Costs dropped, from about 15$ per day for Glue down to only 2$ per day!
Closing Thoughts
Always expect that things can go wrong - if it can go wrong, it probably will.
Build safeguards to protect your downstream processes from corrupted or inconsistent data.
Learn from your mistakes and do not be afraid to talk about it!
Thanks for reading, and I hope you found it helpful :)
Cheers, Geri

Geri is a Senior Cloud Consultant at superluminar.
He is passionate about clean code, well architected applications and new technologies.
You can follow on Geri on LinkedIn.
Or follow his cats on Instagram.