Batchverarbeitung von Daten aus DynamoDB mit AWS Glue

In der heutigen serverless Welt wird häufig DynamoDB als Datenbank eingesetzt. DynamoDB bietet als serverless NoSQL Datenbank eine nahezu unbegrenzte Kapazität und ist in der Lage sowohl Daten schnell aufzunehmen als auch einen schnellen Lesezugriff zu ermöglichen. In der BI Welt dagegen werden Daten oft in einem Data Lake oder Data Warehouse abgelegt, die dann als Quelle und Ziel für unterschiedliche ETL Jobs oder Reports dienen. Hier wird oft AWS Glue eingesetzt, um einen einheitlichen Zugriff auf die Daten zu ermöglichen. Auch DynamoDB kann als Quelle und Ziel für ETL Jobs genutzt werden, wobei allerdings Read und Write Capacity Units verbraucht werden, was wiederum zu einerseits den produktiven Betrieb der Tabelle beeinflussen kann oder zu over provisioning führt und damit auch zu höheren Kosten. Eine Lösung kann sein, statt der direkten Verarbeitung von Daten aus DynamoDB einen Export in S3 zu erzeugen und diesen zu verarbeiten. Dieses Vorgehen kann auch noch andere Vorteile bieten. Zum Beispiel ist es möglich bei einem Rerun eines Jobs denselben Input zu nutzen und somit konsistente Ergebnisse zu produzieren. Auch wenn zwei Jobs dieselbe Tabelle als Quelle haben, ist nicht garantiert, dass auch der Inhalt zur Ausführungszeit identisch ist. Für dieses Beispiel habe ich eine sehr einfache Tabelle angelegt, die nur ein item enthält und URLs einem Satz von Keywords zuordnet.
S3 Exports können zum Beispiel mit der aws cli erstellt werden, sobald das Point-In-Time-Recovery Feature eingeschaltet ist. Mit den Standardeinstellungen wird im angegebenen Bucket ein snapshot angelegt:
aws dynamodb export-table-to-point-in-time \
--table-arn arn:aws:dynamodb:eu-central-1:123456789012:table/websites \
--s3-bucket dynamodb-export-123456789012 \
--region eu-central-1
{
"ExportDescription": {
"ExportArn": "arn:aws:dynamodb:eu-central-1:123456789012:table/websites/export/01630069516214-c156273f",
"ExportStatus": "IN_PROGRESS",
"StartTime": "2021-08-27T15:05:16.214000+2:00";
"TableArn": "arn:aws:dynamodb:eu-central-1:123456789012:table/websites",
"TableId": "Some UUID",
"ExportTime": "2021-08-27T15:05:16.214000+2:00",
"ClientToken": "Some UUID",
"S3Bucket": "dynamodb-export-123456789012",
"S3SseAlgorithm": "AES256:",
"ExportFormat": "DYNAMODB_JSON"
}
}
In S3 findet sich der Export dann unter s3://dynamo-export-XXXXXXX/AWSDynamoDB/01630069516214-c156273f/, das Ende der
S3 URL ist also das Ende der Export ARN. Das ist ziemlich praktisch, weil dieser Teil etwas kryptisch und nicht
vorhersagbar ist. Natürlich lässt sich das auch über die API machen und damit einfach in einer Step Function
integrieren, um die export ARN in den nachfolgenden Verarbeitungsschritten wieder zu benutzen. Im Subfolder data finden
sich dann auch tatsächlich die Daten in einem oder mehreren gz Files, das in unserem Fall JSON Daten enthält. Hier
können wir einfach einen Glue Crawler darauf ansetzen. Man sollte allerdings plain JSON und md5 Files exkludieren, da die
Exports sehr viele Prüfsummen und Metadaten in JSON enthalten und der Crawler sonst für alle Objekte versucht die
Struktur zu erkennen und jeweils eine Tabelle in der Datenbank anlegt. Das Ergebnis ist dann eine Tabelle mit einer
Spalte, item.

Wir können uns jetzt den Typ von item genauer ansehen:
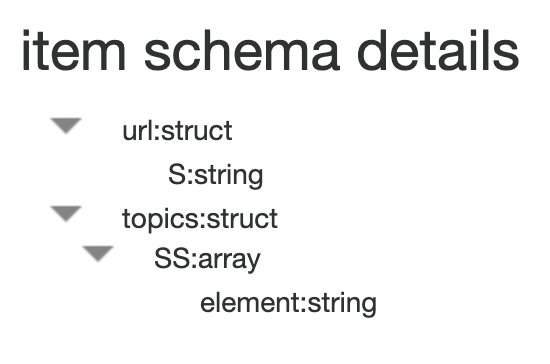
Es handelt sich also um das interne DynamoDB Datenmodell. Das lässt sich natürlich so verwenden, allerdings ist die
Benutzung doch eher hakelig. Für eine Verarbeitung in einem Glue ETL Job müssten wir jetzt jedes Feld einzeln auspacken,
also um an die tatsächliche URL zu kommen auf item['url']['S'] zugreifen anstatt nur auf item['url'], was wiederum
voraussetzt, dass wir die Typen in der Tabelle kennen oder innerhalb des ETL Jobs mit einer extra Logik erkennen.
Angenommen, man hat eine Logik implementiert, die die Typen für alle Spalten erkennt, kann man zum Beispiel eine
ApplyMapping-Transformation benutzen, um alle Spalten auf einmal auszupacken. Besonders, wenn man die Daten wieder in
eine DynamoDB Tabelle zurückschreiben will wird es etwas merkwürdig. Statt zu erkennen, dass die Daten bereits im
DynamoDB-Format vorliegen, wird jetzt aus jeder internen Typdefinition wieder eine neue Map in dem dann die Daten wieder
im internen Format liegen, also wird zum Beispiel aus diesem Objekt (im DynamoDB Format)
{
"item": {
"url": {
"S": "http://example.com"
}
}
}
dieses:
{
"item": {
"url": {
"S": {
"S": "http://example.com"
}
}
}
}
Es würde also bei jedem dieser Schritte eine Schachtelung hinzugefügt werden.
Allerdings gibt es auch ein anderes Exportformat, ION. Der aws cli Aufruf ist nahezu
identisch zu dem JSON-Export, nur muss --export-format ION angegeben werden. Wenn wir wieder einen Crawler laufen
lassen, sieht das Tabellenschema auf den ersten Blick identisch aus.

Allerdings gibt es einen großen Unterschied innerhalb der item-Spalte:

Zwar sind immernoch alle Spaltenwerte in ein struct verpackt, allerdings sind jetzt keine internen DynamoDB Typen mehr
vorhanden. Man braucht also keine eigene Logik mehr um die Daten auszupacken, ein einfaches spark select statement in
Glue reicht vollkommen aus. In einer Map-Transformation kann man dann einfach mit item['url'] auf die urls
zugreifen.
Eine andere Lösung, die ich hier nur am Rande erwähnen möchte, ist aus einer Tabelle mit aktiviertem Point in Time Recovery eine neue Tabelle zu erstellen. Diese ist dann unabhängig von der Originaltabelle und kann direkt in Glue verarbeitet werden. Der Vorteil dabei ist, dass keine zusätzliche Logik gebraucht wird um auf den Abschluss des Exports zu warten. Das ist allerdings auch mittlerweile recht einfach möglich mit der AWS Stepfunctionsintegration von AWS APIs. Der Nachteil bei dieser Methode ist allerdings, dass man sich wieder Gedanken um die Provisionierung von IOPs machen muss. Wählt man feste IOPs, so kann man eben auch nur maximal in der provisionierten Geschwindigkeit lesen, wählt man dagegen das On Demand Capacity Model, geht Glue beim Lesen aus der Tabelle von 40000 provisionierten Read Capacity Units aus. Zum ersten Zeitpunkt des Lesens ist die Tabelle aber noch nicht skaliert und braucht eine Weile, bis genügend Partitions im Hintergrund angelegt wurden. Danach ist die Tabelle warm und kann fortlaufend schnell gelesen werden. Während der Skalierungsphase kommit es allerdings in der Regel zu Lesefehlern wegen des Überschreitens der in dem Moment verfügbaren Kapazität, der Job muss dann neu gestartet werden.
Fazit: Eine Batchverarbeitung von Daten aus Dynamo aus einem Export ist recht einfach möglich und das ION-Format erleichtert das Ganze sehr stark.
