
Orchestrierung von Lambda Funktionen mit AWS Step Functions
June 19, 2018Heute möchte ich euch anhand eines praktischen Beispiels eine Einführung in AWS Step Functions geben. Wir werden eine bestehende AWS Lambda Funktion in ihre einzelnen Bestandteile aufsplitten und in eine State Machine umbauen, die es uns ermöglicht, die Logik der Lambda Funktion über die Limits einer einzelnen Lambda Funktion hinaus zu skalieren.
Stellt euch folgende Situation vor: ihr habt unter Zuhilfenahme des Serverless Frameworks eine Lambda Funktion deployed, die per Cloudwatch Events 1x pro Tag aufgerufen wird, strukturierte Daten von einer externen Datenquelle liest, und zur Weiterverarbeitung nach S3 schreibt. Die externe Datenquelle stellt eine API mit Paginierung bereit und euer Code sieht in etwa so aus:
data = []
offset = 0
while (True):
rows = fetch_from_external_datasource(offset)
if len(rows) == 0:
break
data.extend(rows)
offset = offset + 25
persist_to_s3(data)
Nun stellt ihr beim Betrachten der Metriken eurer Funktion in AWS Cloudwatch fest, dass sich sowohl die Ausführungszeiten, als auch der Speicherverbrauch der Lambda Funktion gefährlich nahe am Limit bewegen. Antwortet die externe Datenquelle einmal langsamer als erwartet, oder werden die zurückgelieferten Daten deutlich mehr, wird eure Funktion nach maximaler Ausführungsdauer oder Erreichen des Speicher-Limits abgebrochen, ohne ihren Job vollständig ausgeführt zu haben.
Hier kommen euch Step Functions zu Hilfe. Step Functions sind State Machines mit einer maximalen Ausführungsdauer von derzeit einem Jahr. Indem ihr eure Logik also in kleinere Stücke zerlegt, die jeweils die maximale Ausführungsdauer einer Lambda Funktion ausnutzen können, habt ihr eine Möglichkeit, eurem Import Job die benötigte Zeit zur Verfügung zu stellen.
Aus eins mach viele!
Schauen wir uns den Code oben noch einmal in Ruhe an. Wir initialisieren eine leere Datenstruktur, die wir nach und nach mit Daten füllen (data = []), und einen Iterator, den wir für die Paginierung des externen Datensets benutzen (offset = 0). Wir extrahieren:
def initialize():
data = []
offset = 0
Als nächstes fragen wir unsere Datenquelle nach Daten in 25er Inkrementen an. Unsere Abbruchbedingung hier ist schlicht “bekommen wir noch Daten?”. Wir extrahieren:
def fetch(offset):
rows = fetch_from_external_datasource(offset)
if len(rows) == 0:
break
data.extend(rows)
offset = offset + 25
Zu guter Letzt schreiben wir die gesammelten Daten in unsere Persistenz (hier S3). Wir extrahieren:
def persist():
persist_to_s3(data)
Shared State
Beim Design unserer State-Machine müssen wir bedenken, dass wir zwischen Lambda Funktionen keinen echten Shared Memory zur Verfügung haben. Allerdings bekommen wir durch Step Functions den aktuellen State in jede Funktion als ersten Parameter hereingereicht, und geben aus Funktionen neuen State zurück. Somit können Funktionen den State lesen und schreiben!
Migration: offset
Dies machen wir uns zu Nutzen, und migrieren als Erstes offset in den State. initialize wird zu:
-def initialize:
+def initialize(state):
data = []
- offset = 0
+ state['offset'] = 0
+ return state
Dieser “shared state” ist allerdings limitiert (https://docs.aws.amazon.com/step-functions/latest/dg/limits.html#service-limits-task-executions), und eignet sich somit nicht für das Durchreichen der von der externen Datenquelle gelieferten Nutzdaten (data). Doch hierzu später mehr.
Unsere fetch Funktion bauen wir nun entsprechend um, so dass sie das nun im State gehaltene offset liest und nach jedem Aufruf inkrementiert:
-def fetch(offset):
- rows = fetch_from_external_datasource(offset)
+def fetch(state):
+ rows = fetch_from_external_datasource(state['offset'])
if len(rows) == 0:
break
data.extend(rows)
- offset = offset + 25
+ state['offset'] = state['offset'] + 25
+ return state
Migration: data
Bleibt die Frage, wo wir nun die Nutzdaten speichern, denn wir haben ja keinen Shared Memory, und das State Objekt ist zu klein, um alle Daten zu halten. Wir entscheiden uns hier, als “Cache” eine Datei in S3 zu nutzen, die wir während der Initialisierung (initialize) leeren, in unserem Iterator (fetch) befüllen, und in unserer Persistierung (persist) an den Ziel-Ort verschieben (bei Bedarf können wir später vor unseren persist Schritt auch noch Validierung oder Sanitisierung hinzufügen). Wir ändern:
def initialize(state):
- data = []
+ empty_s3_cache()
+
state['offset'] = 0
return state
def fetch(state):
+ data = read_from_s3_cache()
+
rows = fetch_from_external_datasource(state['offset'])
if len(rows) == 0:
break
data.extend(rows)
+ write_to_s3_cache(data)
state['offset'] = state['offset'] + 25
return state
-def persist:
- persist_to_s3(data)
+def persist(state):
+ copy_s3_cache_to_final_location()
+
Flow und Abbruchbedingung
Wir haben nun die Einzelbestandteile unserer Job Logik in einzelne Funktionen ausgelagert. Als nächstes müssen wir die Orchestrierung in einer State Machine abbilden. Hierfür brauchen wir zunächst eine Abbruchbedingung. Schauen wir in unseren Code - bisher brechen wir simpel aus der Ausführung aus, sobald wir keine Daten mehr von der externen Datenquelle erhalten (if len(rows) == 0: break). Wir behalten die Logik bei, schreiben aber das Ergebnis unseres “sind wir schon fertig?” Checks in den State, damit unsere State Machine sich um den Abbruch kümmern kann:
def initialize(state):
empty_s3_cache()
+ state['continue'] = True
state['offset'] = 0
return state
rows = fetch_from_external_datasource(state['offset'])
if len(rows) == 0:
- break
+ state['continue'] = False
data.extend(rows)
write_to_s3_cache(data)
Die State-Machine
Mit Hilfe des serverless Plugins serverless-step-functions können wir unsere State-Machine direkt in unserer serverless.yml definieren. Wir sitzen nun auf allen Bestandteilen, um die finale State Machine zusammenstecken zu können. Wir haben unsere einzelnen Funktionen (initialize, fetch, persist), unseren Iterator (offset) und eine Abbruchbedingung (continue) im State. Für den Abbruch benutzen wir eine der Step Functions Primitiven (Choice) und prüfen auf unsere Abbruchbedingung continue. Weitere Primitiven findet ihr in der AWS Dokumentation). Unsere fertige State Machine sieht danach so aus:
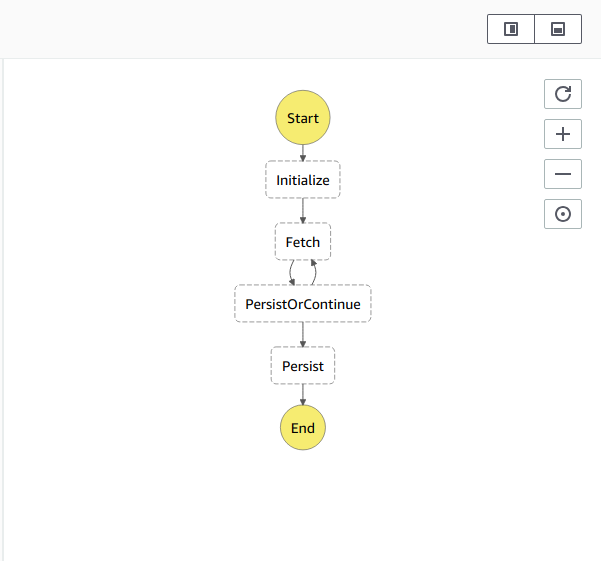
stateMachines:
fetchDataFromExternalDatasource:
definition:
StartAt: Initialize
States:
Initialize:
Type: Task
Resource: arn:aws:lambda:......
Next: Fetch
Fetch:
Type: Task
Resource: arn:aws:lambda:......
Next: PersistOrContinue
PersistOrContinue:
Type: Choice
Choices:
- Variable: "$.continue"
BooleanEquals: true
Next: Fetch
- Variable: "$.continue"
BooleanEquals: false
Next: Persist
Persist:
Type: Task
Resource: arn:aws:lambda:......
End: true
Zusammenfassung
AWS Step Functions eignet sich hervorragend, um komplexere oder länger laufende Applikationen mit Hilfe von Lambda zu orchestrieren, jedoch auch für eine Vielzahl weiterer Anwendungsfälle. Habt ihr selber schon mit Step Functions experimentiert, oder benutzt ihr Step Functions bereits in Produktion? Lasst uns gerne per Kommentar wissen, wie eure Erfahrungen sind!